
Mas leido
Building Stories
Modo Rua: Redefiniendo el desarrollo de aplicaciones mediante iteración centrada en el usuario Ago 23
Building Stories
NuStories: Adaptación de productos para clientes fanáticos en varios países Oct 30
Culture & Values
Cómo los valores y la cultura de Nu dan forma a los productos que creamos Ago 7
Carreras
Reunimos a grandes mentes de diversos orígenes que permiten la discusión y el debate y mejoran la resolución de problemas.
Conoce más sobre nuestras carreras




Autores: El equipo de Data Science de la Experimentation Platform de Nubank está conformado por Abel Borges, Brando Morais, Luís Assunção, Paulo Rossi y Ramon Vilarino (en orden alfabético).
Ninguna funcionalidad de la plataforma sería posible sin el apoyo de todo el squad — un agradecimiento especial a Thiago Nunes (PM), Thiago Parreiras (Product Lead) y Miguel Bitarello (Engineering Lead).
Introducción
La prueba A/B es una piedra angular del desarrollo de productos en Nubank. Nos permite tomar decisiones informadas por datos al comparar diferentes versiones de un producto o característica para ver cuál funciona mejor. Este enfoque riguroso garantiza que cada cambio que implementamos esté respaldado por evidencia empírica, lo que conduce a una mejora continua y a una experiencia superior para el usuario.
Sin embargo, un desafío persistente en la experimentación es el problema de la sensibilidad del experimento. A menudo, los efectos que buscamos medir son sutiles o pequeños, lo que dificulta detectarlos con significancia estadística. Esta limitación puede obstaculizar nuestra capacidad para identificar cambios y optimizar nuestros productos de manera efectiva. Para superar esto, nuestro equipo se embarcó en un viaje para explorar técnicas avanzadas de reducción de varianza con el fin de mejorar el poder estadístico.
Mejorar el poder estadístico se traduce directamente en una mayor precisión para nuestras estimaciones, lo que a su vez reduce la duración de los experimentos. Esto permite una iteración más rápida y segura.
Entre los enfoques que investigamos, el ″Experimento Controlado utilizando Datos Pre-Experimentales″ (CUPED) se destacó. CUPED es un método estadístico que aprovecha los datos anteriores al experimento para reducir la variabilidad de las métricas clave. Al tener en cuenta las diferencias de referencia entre las unidades experimentales, CUPED puede mejorar significativamente el poder estadístico de nuestros experimentos, facilitando la detección de efectos incluso más pequeños, pero aun así significativos.
Este artículo comparte las 3 lecciones clave que aprendimos del proceso desafiante pero gratificante de implementar CUPED dentro de la sólida plataforma de experimentación de Nubank. Estas ideas ofrecen una orientación valiosa para cualquier organización que busque mejorar la precisión y la eficiencia al escalar sus esfuerzos de pruebas A/B.
Descubre las oportunidades
Antecedentes
CUPED fue introducido, por primera vez, por los investigadores de Microsoft Deng y otros (2013) y ha sido ampliamente utilizado en empresas como Netflix, Booking, Eppo, Walmart y muchas otras. Notas de otros investigadores (Lin (2013), Deng y Hu (2015), Deng y otros (2023)) destacan la relación de CUPED con la regresión lineal, y cómo diferentes supuestos en CUPED se mapean a distintas especificaciones de regresión.
Supongamos que nuestro experimento tiene una métrica objetivo Y que se calcula utilizando todos los eventos de un cliente determinado después de que este es expuesto al experimento. Estamos interesados en estimar el Efecto Promedio del Tratamiento (ATE), por lo que calculamos la diferencia de medias entre el grupo de tratamiento y el grupo de control,
donde Δ Es un estimador insesgado del ATE (Efecto Promedio del Tratamiento). Asumamos que podemos calcular una covariable X utilizando eventos que ocurrieron antes de la exposición del cliente al experimento. Con esto, podemos escribir:
donde θ es un parámetro escalar. Como los sujetos fueron asignados aleatoriamente entre los grupos de control y tratamiento,E(Xt) -E(Xc)= 0 y, por lo tanto, Δadjusted también es un estimador insesgado del ATE.
Δadjusted también es un estimador insesgado del ATE.
El objetivo es elegir un valor para θ que reduzca la varianza del resultado Δadjusted tanto como sea posible. Usando la expresión para la varianza de la combinación lineal de dos variables aleatorias, podemos expandir la varianza para el adjusted:
Δadjusted tanto como sea posible. Usando la expresión para la varianza de la combinación lineal de dos variables aleatorias, podemos expandir la varianza para el adjusted:
Al establecer su primera derivada igual a cero, podemos determinar el valor óptimo, θ*, que minimiza esta varianza:
Y finalmente tenemos:
Una elección natural para X son las mediciones de Y antes de la exposición; por ejemplo, las métricas transaccionales clave para un banco suelen presentar una fuerte correlación serial (es decir, correlación de la métrica consigo misma en el pasado). Sin embargo, esta demostración se aplica a cualquier variable.
Note que se escribimos θ* en términos de las covarianzas entre las observaciones unitarias en lugar de entre promedios, entonces podemos escribir:
donde θc=Cov(Xc,,Yc)/Var(Xc) y θt=Cov(Xt,,Yt)Var(Xt). En otras palabras, es un promedio ponderado de dos parámetros de cada grupo en términos de sus varianzas muestrales.
Tenga en cuenta que θc y θt son coeficientes de regresiones lineales simples por grupo, y θ* es una combinación de ambos. Se pueden encontrar más detalles en Lin, Sección 2 (o 3).
Lección 1: Tenga en cuenta las varianzas desiguales.
Cuando los grupos de control y de tratamiento tienen el mismo tamaño, θ* se puede aproximar a partir de estadísticas combinadas, tal como se describe en Deng et al. (2013):
lo que resulta en un Δpooled. Sin embargo, cuando los grupos del experimento tienen diferentes tamaños de muestra (nc ≠ nt) y el tratamiento cambia la correlación serial de la métrica (Cov(Xc,Yc) ≠ Cov(Xt,Yt) ), la varianza del Δpooled puede ser mayor que la varianza del estimador ingenuo Δ.
Cuando se simulan escenarios con grupos altamente desiguales (una división de 90%/10%) y una covarianza del grupo de tratamiento tres veces mayor que la del grupo de control, las distribuciones del ATE demuestran una eficiencia reducida con una estimación combinada (pooled estimation), como se ilustra en el siguiente gráfico.
En Nubank, originalmente implementamos CUPED estimando θpooled para cada par de variantes en todos los experimentos. Sin embargo, llevamos a cabo múltiples experimentos que violan las suposiciones de este estimador original. Lin (2013) demostró que Δ*adjusted es al menos tan eficiente como ambos Δ, el Δpooled. Siguiendo sus conclusiones, evaluamos si este cambio sería significativo para nuestras métricas y decidimos cambiar nuestra implementación para usar θ*. Aunque aparentemente menor, este cambio mejoró significativamente la robustez y precisión de nuestros análisis, llevando a conclusiones experimentales más confiables.
Lección 2: Cómo Definimos una Ventana de Retrospección Estándar de 42 Días
Siguiendo la descomposición de θ* como una suma ponderada de coeficientes similares a θ-dentro de cada grupo, la varianza del Δ*adjusted puede reformularse como una función de las desviaciones estándar de la métrica y las correlaciones seriales (pt, pc) entre sus versiones posterior y previa a la exposición, donde
 π ∈ (0,1) es la tasa de muestreo del grupo de tratamiento:
π ∈ (0,1) es la tasa de muestreo del grupo de tratamiento:
Tenga en cuenta que cuanto mayor sea la correlación (en términos absolutos) entre la métrica posterior a la exposición Y y la métrica anterior a la exposición X, mayor será la reducción de varianza. Como se señaló en la sección de antecedentes, un método sencillo es establecer X igual a Y en el pasado, lo que naturalmente lleva a utilizar la misma variable como covariable de control durante la ventana de observación pre-experimental. Sin embargo, esto plantea la pregunta: ¿Cómo podemos determinar el período óptimo de agregación de métricas pre-experimentales para CUPED?
Nubank ofrece una cartera diversa de productos y servicios, que van desde sus ofertas fundamentales de tarjetas de crédito hasta su creciente marketplace de compras. Dada esta diversidad inherente, cada producto opera dentro de su propio mercado distinto y apunta a un segmento diferente de la base de clientes. Por ejemplo, la estacionalidad de un usuario que busca vuelos en nuestro marketplace es muy diferente a la de aquellos que invierten en criptoactivos.
Idealmente, cada métrica y experimento tendría su propia ventana pre-experimental. Sin embargo, este nivel de flexibilidad y sobrecarga de implementación no es actualmente factible en nuestra plataforma. Por lo tanto, elegimos una ventana genérica que capturaría adecuadamente la mayor parte del comportamiento pasado del usuario sin aumentar significativamente los costos de la pipeline (tubería de datos).
Para ello, ejecutamos varias simulaciones, muestreando sujetos de nuestros experimentos con diferentes tamaños y duraciones de muestra. Este enfoque nos permitió incorporar datos simulados con efectos de tratamiento reales para obtener la ventana óptima. Nuestro análisis se concentró en ventanas de tiempo que eran múltiplos precisos de siete, lo que capturó y abordó los patrones semanales presentes en los datos.Los resultados promedio de la reducción de varianza, presentados en función de la ventana de retrospectiva (lookback window), se detallan a continuación.
Seleccionamos una ventana de retrospectiva fija de 42 días para nuestro análisis debido a su desempeño equilibrado en todas las métricas y experimentos. Este período de tiempo presentó un buen punto de equilibrio entre la minimización de la varianza y la gestión de los costos computacionales de nuestra pipeline de métricas. También descubrimos que una ventana de 42 días es suficiente para capturar la dinámica promedio del negocio, en particular al abarcar al menos un ciclo de facturación de la tarjeta de crédito, asegurando una visión integral del comportamiento del cliente y la actividad financiera.
Sin embargo, el impacto real de CUPED varía significativamente a lo largo de nuestro diverso ecosistema. El siguiente gráfico ilustra la distribución de la reducción de varianza que observamos en la práctica en cientos de métricas en miles de comparaciones de experimentos diferentes.
Esta distribución revela un par de ideas clave:
En última instancia, esto demuestra que si bien es un desafío encontrar una ventana de retrospectiva perfecta y universal (one-size-fits-all), nuestro período estandarizado de 42 días proporciona una reducción de varianza significativa para la gran mayoría de nuestras métricas. Encontrar buenos factores genéricos que expliquen la varianza es un desafío.
Lección 3: El efecto de contracción
El camino hacia la integración completa de CUPED no fue solo técnico. Una de las principales razones por las que inicialmente dudamos en convertirlo en la vista predeterminada en nuestra plataforma de experimentación fue el cambio en la forma en que se interpreta el Efecto Promedio del Tratamiento (ATE). Aunque el nuevo estimador es más preciso, su estimación puntual también cambia y puede diferir significativamente del aumento (lift) sin ajustar, o raw (en bruto), al que nuestros equipos estaban acostumbrados.
Esta discrepancia se complica aún más por nuestro uso del aumento relativo (relative lift) como el resultado principal en la plataforma, calculado como el ATE dividido por la media de la muestra del grupo de control.
Explicar una métrica que combina un numerador ajustado con un denominador sin ajustar agrega otra capa de complejidad. Esto requirió una inversión significativa en capacitación y horas de consulta (office-hours) con nuestros usuarios y stakeholders para garantizar que entendieran no solo que los resultados eran más precisos, sino por qué. Este esfuerzo fue crucial para generar confianza y evitar la mala interpretación de los resultados ajustados.
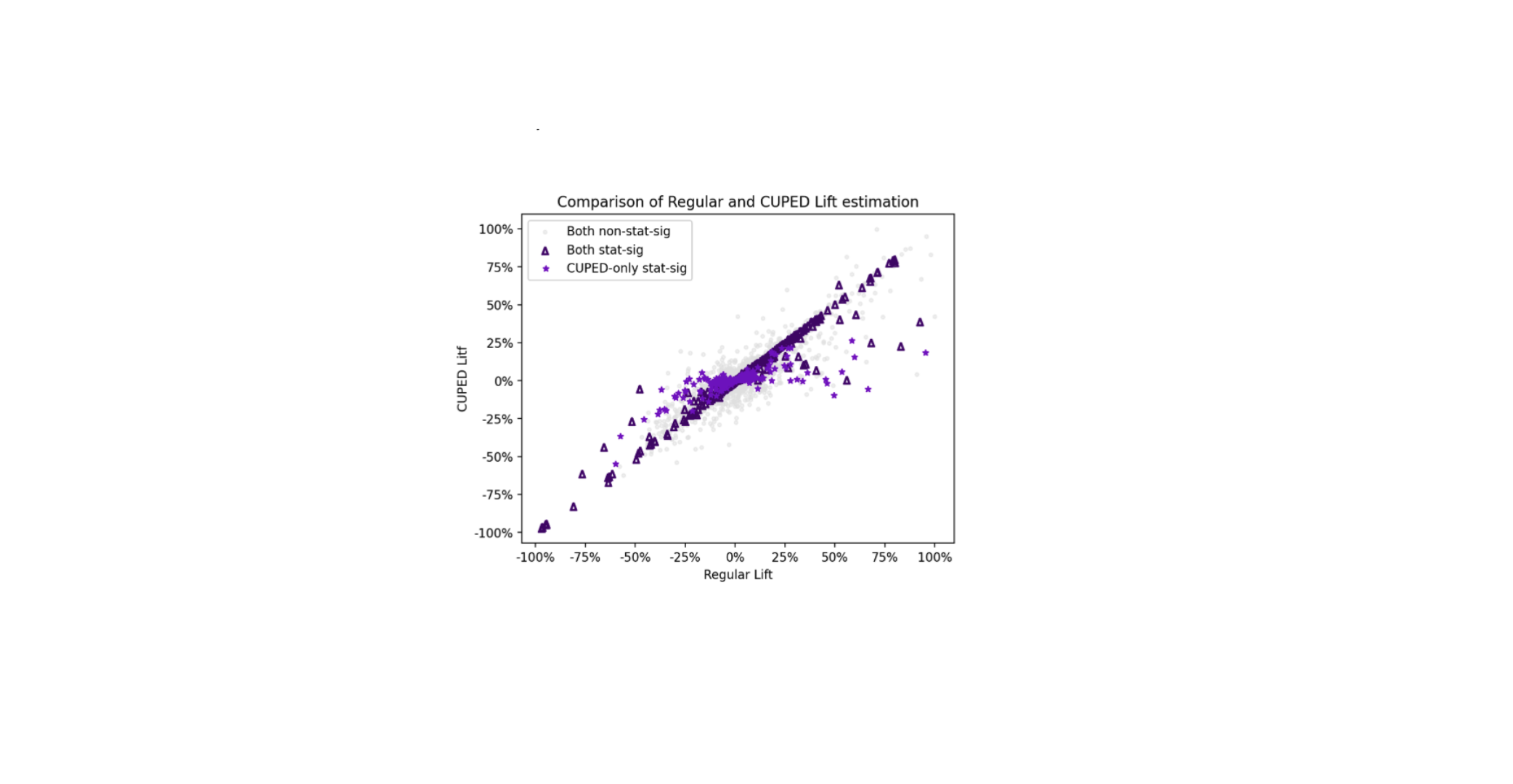
El siguiente diagrama de dispersión compara el aumento relativo (relative lift) estimado por nuestro análisis estándar (″Aumento Regular″) con el aumento relativo estimado usando CUPED (″Aumento CUPED″) en miles de experimentos y en cientos de métricas binarias y continuas.
El gráfico revela tres ideas clave. Primero, el denso grupo de puntos es simétrico alrededor de la línea y=x. Esta observación empírica se alinea con la teoría de que el aumento ajustado por CUPED sigue siendo un estimador insesgado.
Segundo, las estrellas morado claro representan experimentos donde el análisis estándar no logró encontrar un resultado estadísticamente significativo, pero el análisis ajustado por CUPED sí lo logró. Aunque la significancia estadística es una definición arbitraria (y aplicamos algunas correcciones conservadoras como Bonferroni en nuestros paneles de control de métricas múltiples), estos puntos podrían representar ″victorias ocultas″ y ″advertencias perdidas″, descubiertas debido a la capacidad de CUPED para aumentar el poder estadístico.
Tercero, una mirada más cercana a estos puntos también revela un ″efecto de contracción″ sutil pero importante: el aumento de CUPED para estas estrellas azules a menudo está más cerca de cero que la estimación del análisis regular. Esta contracción no es una debilidad, sino una característica crucial que ayuda a mitigar los errores de Tipo M (magnitud). Al lograr un mayor poder para experimentos originalmente dimensionados para el estimador ingenuo, CUPED reduce la estimación puntual hacia el verdadero efecto del tratamiento en comparaciones estadísticamente significativas. Estas estimaciones reducidas se ilustran como triángulos morado oscuro en el gráfico.
Conclusión
La implementación de CUPED de Nubank en su Plataforma de Experimentación arrojó 3 ideas significativas. Primero, es crucial ser consciente de las varianzas y tamaños de muestra desiguales entre los grupos de control y tratamiento, ya que el uso de un estimador agrupado para theta (θpooled) puede disminuir la precisión, especialmente cuando el tratamiento cambia la covarianza serial de la métrica. La compañía cambió a un estimador de promedio ponderado más robusto (θ*) para abordar esto, lo que mejoró la precisión de su análisis.
Segundo, se eligió una ventana de retrospectiva estándar de 42 días como una compensación práctica. Si bien el período óptimo de datos pre-experimento varía con diferentes métricas y escenarios de experimento, se encontró que esta ventana fija reduce eficazmente la varianza para la mayoría de las métricas, siendo computacionalmente eficiente.
Por último, observamos un efecto de contracción donde los aumentos ajustados por CUPED para resultados estadísticamente significativos a menudo están más cerca de cero que el análisis regular. Esta es una característica valiosa que ayuda a mitigar los errores de Tipo M al corregir los efectos sobreestimados y proporciona una estimación más precisa y realista.
Basándonos en el éxito de CUPED, estamos explorando activamente nuevas vías para la reducción de la varianza. Esto incluye investigar la incorporación de covariables adicionales y desarrollar metodologías robustas para llevar a la plataforma técnicas avanzadas de reducción de la varianza a escala en todos nuestros esfuerzos de experimentación. Nuestro trabajo continuo en esta área refuerza el compromiso de Nubank de aprovechar métodos de experimentación sofisticados, apoyando en última instancia nuestra misión de tomar continuamente mejores decisiones de productos que beneficien a nuestros clientes.
Descubre las oportunidades