
most read
Software Engineering
Why We Killed Our End-to-End Test Suite Sep 24
Culture & Values
The Spark Of Our Foundation: a letter from our founders Dec 9
Software Engineering
The value of canonicity Oct 30
Careers
We bring together great minds from diverse backgrounds who enable discussion and debate and enhance problem-solving.
Learn more about our careers




Author: Daniel Braithwaite, Misael Cavalcanti, and Hiroto Udagawa
The work described here is a collaborative effort by many engineers at Nubank (alphabetical): Abhishek Shivanna, Arissa Yoshida, Austin McEver, Brian Zanfelice, Cristiano Breuel, Evan Wingert, Fabio Souza, Felipe Meneses, Helder Dias, Henrique Fernandes, Liam O’Neill, Marcelo Buga, and Matheus Ramos. We also thank Rohan Ramanath, Daniel Silva, and Guilherme Tanure for their support.
Translations Reviewers: Cinthia Tanaka and Kevin Rossell
This is the third part of a series of blog posts about modeling customer finances through foundation models. Read our first blog post for an introduction to the problem. Review our second blog post for more context on how we formulate our foundation models for transaction data.
In our previous blog posts on transaction-based customer foundation models, we demonstrated how self-supervised learning (pre-training) can produce general (unsupervised) embeddings that represent a customer’s behavior from transaction data. These embeddings are not optimized for any particular task and can be applied to a variety of problems. However, if we want to achieve optimal performance on a specific task, we can further refine the transformer and its embeddings through a process called supervised fine-tuning.
Our supervised fine-tuning process is a secondary step in which we take a pre-trained model and add a linear layer, called the prediction head, to predict the given label, such as a binary classification, multi-class, or regression target. The input to this prediction head is the final token embedding, denoted the user embedding, from the output of the causal transformer. We then optimize the transformer simultaneously with the prediction layer to minimize the loss (i.e., cross entropy, MSE). Hence, after supervised fine-tuning, the embedding is tailored to the given task. The figure below (on the left) shows this process. In addition, the right-hand figure below shows the 1.68% relative improvement in AUC achieved by finetuning across several benchmark tasks.
A primary motivation for developing foundation models for transaction data is to capture the signal in this data more effectively through an improved (learned) encoding. Moreover, as seen in other fields, we hypothesize that as we scale these models (e.g., more transaction history, larger models, more data), the signal captured from the transaction data will become richer, leading to further improved performance on downstream tasks. Another benefit of these foundation models is that they alleviate the need for manually engineering features from the sequential transaction data. However, not all data that is useful is sequential. Rather, in many cases, data is tabular in nature (e.g., bureau information), which means we need a solution that allows us to incorporate both sequential and tabular data into a final solution.
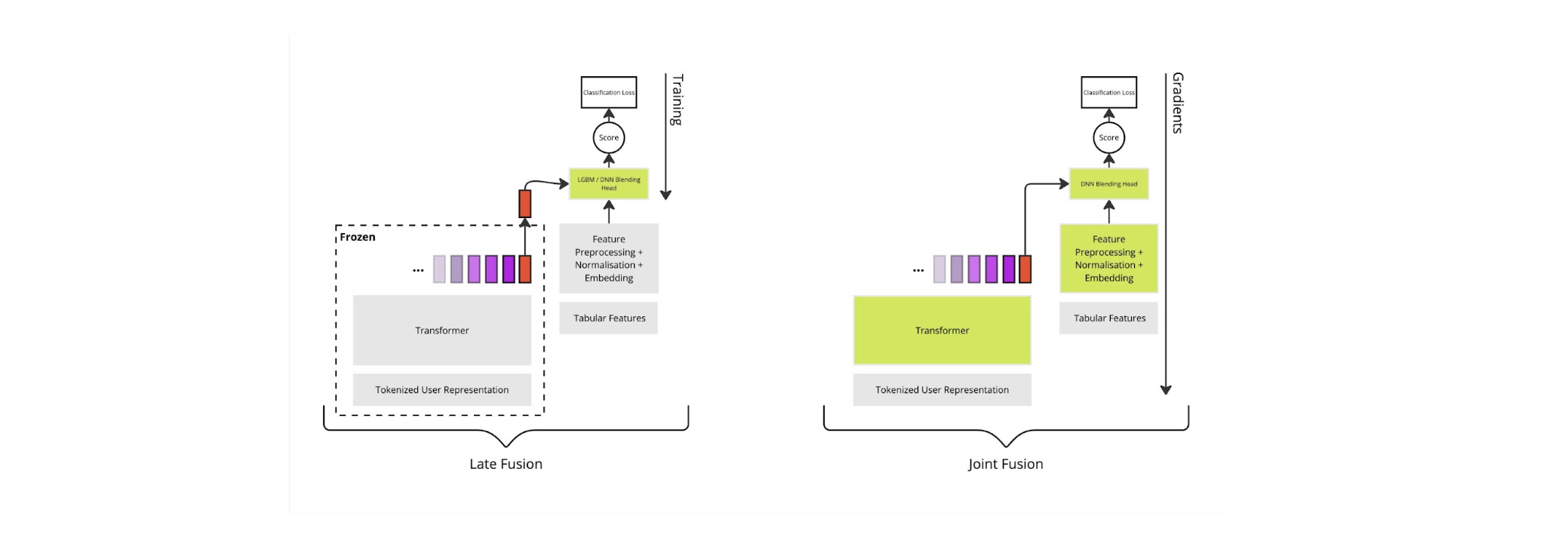
The process of combining embeddings with tabular features is known as fusion (or blending). In the remainder of this blog post, we discuss fusion, and finally, we introduce an architecture that incorporates these features into the transformer finetuning procedure. The naive approach to blending is to use Gradient-boosted tree models (GBT; e.g., XGBoost [2] or LightGBM [3]) to combine the tabular data because they are generally considered state-of-the-art [1]. Alongside these tabular features, finetuned embeddings can be passed into the GBT training, a process denoted late fusion [8]. However, late fusion is suboptimal because the finetuned embeddings are learned separately from the tabular features.
In contrast to late fusion, we propose a joint fusion-based [8] training procedure. This procedure jointly optimizes the transformer alongside the blending model, enabling the transformer to better capture information not present in the tabular features. The figure below shows a high-level comparison between late and joint fusion (green blocks indicate which sections of the model are trained).
Unfortunately, GBTs are not differentiable and, hence, are incompatible with joint fusion. Motivated by this incompatibility, we invested in DNN-based tabular feature networks. However, despite some recent work showing that DNNs can be competitive with GBTs [4], the performance of DNN tabular feature networks can vary drastically between problems. For example, one survey paper [5] evaluated 19 tabular feature models (NN + GBT) on 176 datasets, and each model performed the best on one dataset and the worst on another, making it challenging to adopt a one-size-fits-all approach.
The first step in our approach was to achieve parity between DNNs and GBT models on only the tabular features. We selected the DCNv2 architecture [6] as it has shown success on related problems at a large scale (e.g., used by Google [6]). However, initial results showed much worse performance (-0.40%) for the DNN-based DCNv2 models compared to the GBTs.
In a recent paper [7], the authors found that embedding numerical attributes achieved significant gains when modeling numerical tabular features in DNNs. These numerical embeddings are constructed using periodic activations at different, learned frequencies. We combined this with trainable embedding tables to also facilitate categorical feature embeddings. Incorporating this embedding strategy into the DCNv2 model allowed us to achieve parity with GBTs on many of our internal problems.
Despite achieving parity with only tabular features, the last challenge to overcome was incorporating transformer-based user embeddings into these models while maintaining or beating the GBT model’s performance with DNNs. Three key factors were critical in achieving this. Firstly, we use the DCNv2 to process the embedded tabular features and project the result into a low-dimensional embedding. This feature embedding is concatenated with the transformer-based embedding, and a multi-layer perceptron makes the final prediction. Secondly, adding regularization in the form of weight decay and/or dropout to the DCNv2 cross layers reduced overfitting. Finally, adding normalization to the transformer-based embeddings improved the consistency of the DCNv2, allowing the DNN model to consistently and reliably beat the GBTs. The figure below shows the average relative improvement in AUC for a collection of benchmark tasks across several versions of our DNN model. We see that only when combining the DCNv2 with the numerical embeddings are we able to beat the baseline.
Despite the challenges in using DNNs with tabular data, we achieved a model that works well for our current tasks of interest using a combination of the DCNv2 [6], numerical embeddings, categorical feature embeddings [7], and regularization. Using this DCNv2 model with the aforementioned improvements, we can train the blending model to combine features and the embedding while simultaneously finetuning the transformer model. The figure below shows the tabular feature blending as part of the finetuning process. The right-hand figure below shows the feature pre-processing and embedding in more detail.
In the following figure, we visualize the relative gain in AUC when using joint fusion vs late fusion on the same benchmark tasks as above. As before, the baseline here is a LightGBM model trained on only the features. This demonstrates the advantage of finetuning jointly with tabular features. Importantly, in the case of both late and joint fusion, the improvement is not obtained by adding new sources of information. Rather, the improvement is achieved by automatically learning informative features for the task at hand through finetuning our transaction foundation models.
In this blog post, we began by motivating and introducing a standard supervised finetuning approach for learning embeddings that are tailored for specific tasks. Following this, we introduced joint fusion, which allows us to blend existing tabular feature sets with our embeddings during finetuning. Joint fusion makes it straightforward to provide a lift in performance from our user embeddings while also incorporating any existing tabular feature-based solution. Finally, we demonstrated the lift generated by joint fusion on internal benchmarks.
Series Summary
If you’ve made it this far, take a moment to check out the rest of the blog series for more context and technical depth.
Check our job opportunities
References
[1] Borisov, V., Leemann, T., Seßler, K., Haug, J., Pawelczyk, M., & Kasneci, G. (2022). Deep neural networks and tabular data: A survey. IEEE transactions on neural networks and learning systems.
[2] Chen, T., & Guestrin, C. (2016, August). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining (pp. 785-794).
[3] Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., … & Liu, T. Y. (2017). Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems, 30.
[4] Zabërgja, G., Kadra, A., & Grabocka, J. (2024). Tabular Data: Is Attention All You Need?. arXiv preprint arXiv:2402.03970.
[5] McElfresh, D., Khandagale, S., Valverde, J., Prasad C, V., Ramakrishnan, G., Goldblum, M., & White, C. (2024). When do neural nets outperform boosted trees on tabular data?. Advances in Neural Information Processing Systems, 36.
[6] Wang, R., Shivanna, R., Cheng, D., Jain, S., Lin, D., Hong, L., & Chi, E. (2021, April). Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. In Proceedings of the web conference 2021 (pp. 1785-1797).
[7] Gorishniy, Y., Rubachev, I., & Babenko, A. (2022). On embeddings for numerical features in tabular deep learning. Advances in Neural Information Processing Systems, 35, 24991-25004.
[8] Imrie, F., Denner, S., Brunschwig, L. S., Maier-Hein, K., & Van Der Schaar, M. (2025). Automated ensemble multimodal machine learning for healthcare. IEEE Journal of Biomedical and Health Informatics.
Check our job opportunities