
mais lidos
Life at Nu
Conheça a sede do Nubank em Pinheiros, São Paulo/Brasil jan 11
Design
A nova aparência do Nubank: conheça nossa nova logo maio 17
Culture & Values
Como os valores e a cultura da Nu moldam os produtos que criamos ago 7
Carreiras
Reunimos grandes mentes de diversas origens que permitem a discussão e o debate e melhoram a resolução de problemas.
Saiba mais sobre nossas carreiras




Autores: Daniel Braithwaite, Misael Cavalcanti e Hiroto Udagawa.
O trabalho descrito aqui é um esforço colaborativo de vários engenheiros do Nubank (em ordem alfabética): Abhishek Shivanna, Arissa Yoshida, Austin McEver, Brian Zanfelice, Cristiano Breuel, Evan Wingert, Fabio Souza, Felipe Meneses, Helder Dias, Henrique Fernandes, Liam O’Neill, Marcelo Buga e Matheus Ramos. We also thank Rohan Ramanath, Daniel Silva e Guilherme Tanure pelo apoio.
Tradução técnica: Cinthia Tanaka e Kevin Rossell
Esta é a terceira parte de uma série de postagens no blog sobre modelagem de finanças de clientes por meio de modelos fundacionais. Leia a nossa primeira postagem no blog para uma introdução ao problema. Confira nossa segunda postagem no blog para mais contexto sobre como formulamos nossos modelos de fundação para dados de transações.
Em nossas postagens anteriores sobre modelos fundacionais baseados em transações para clientes, demonstramos como o aprendizado auto-supervisionado (pré-treinamento) pode gerar embeddings gerais (não supervisionados) que representam o comportamento de um cliente a partir de dados de transações. Esses embeddings não são otimizados para nenhuma tarefa específica e podem ser aplicados a uma variedade de problemas. No entanto, se quisermos alcançar um desempenho ideal em uma tarefa específica, podemos refinar ainda mais o transformer e seus embeddings por meio de um processo chamado ajuste fino supervisionado.
Nosso processo de ajuste fino supervisionado é uma etapa secundária na qual partimos de um modelo pré-treinado e adicionamos uma camada linear, chamada de camada de predição, para prever o rótulo fornecido, como uma classificação binária, multi-classe ou alvo de regressão. A entrada para essa camada de predição é o embedding do último token da sequência, denominado embedding do usuário, a partir da saída do transformer causal. Então, otimizamos o transformer simultaneamente com a camada de predição para minimizar a perda (ou seja, entropia cruzada, erro quadrático médio). Assim, após o ajuste fino supervisionado, os embeddings estarão adaptados à tarefa dada. A figura abaixo (à esquerda) mostra esse processo. Além disso, a figura à direita abaixo mostra uma melhoria relativa de 1,68% no AUC alcançada pelo ajuste fino em várias tarefas de benchmark.
Uma motivação principal para o desenvolvimento de modelos fundacionais para dados de transações é capturar o sinal nesses dados de maneira mais eficaz através de uma codificação aprimorada (aprendida). Além disso, como visto em outros campos, hipotetizamos que à medida que escalamos esses modelos (por exemplo, mais histórico de transações, modelos maiores, mais dados), o sinal capturado dos dados de transações se tornará mais rico, levando a um desempenho ainda melhor em tarefas posteriores. Outro benefício desses modelos de fundação é que eles aliviam a necessidade de engenharia manual de features a partir dos dados de transações sequenciais. No entanto, nem todos os dados úteis são sequenciais. Na verdade, em muitos casos, os dados têm natureza tabular (por exemplo, informações de bureau), o que significa que precisamos de uma solução que nos permita incorporar tanto dados sequenciais quanto tabulares em uma solução final.
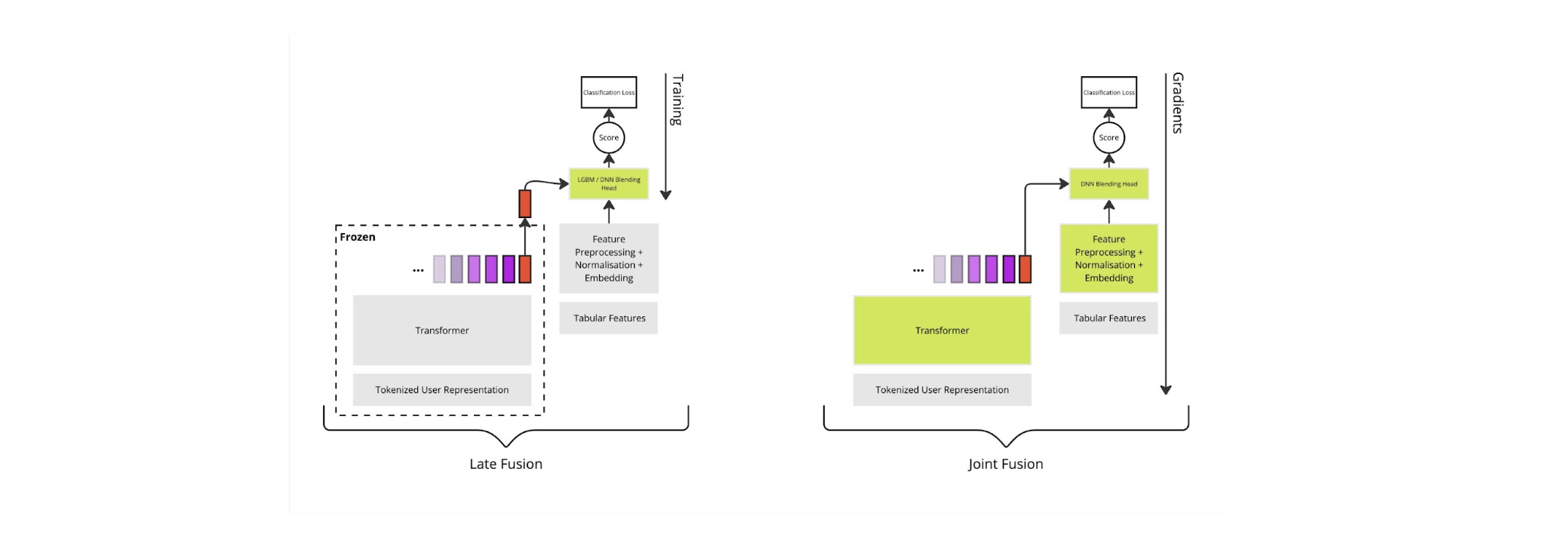
O processo de combinar embeddings com features tabulares é conhecido como fusão (ou blending). No restante deste post, discutimos sobre a fusão e, finalmente, introduzimos uma arquitetura que incorpora essas features no procedimento de ajuste fino do transformer. A abordagem trivial para a fusão é usar modelos de árvores de decisão impulsionadas por gradiente (GBT; por exemplo, XGBoost [2] ou LightGBM [3]), para combinar os dados tabulares, pois geralmente são considerados estado da arte [1]. Junto com essas features tabulares, embeddings ajustados podem ser passados para o treinamento do GBT, em um processo denominado fusão tardia [8]. No entanto, a fusão tardia é subótima porque os embeddings ajustados são aprendidos separadamente das features tabulares.
Em contraste com a fusão tardia, propomos um procedimento de treinamento baseado em fusão conjunta [8]. Este procedimento otimiza conjuntamente o transformer junto com o modelo de fusão, permitindo que o transformer capture melhor informações não presentes nas features tabulares. A figura abaixo mostra uma comparação de alto nível entre fusão tardia e fusão conjunta (os blocos verdes indicam quais seções do modelo são treinadas).
Infelizmente, os GBTs não são diferenciáveis e, portanto, são incompatíveis com a fusão conjunta. Motivados por essa incompatibilidade, investimos em redes de features tabulares baseadas em Redes Neurais Profundas (DNNs). No entanto, apesar de alguns trabalhos recentes mostrarem que DNNs podem ser competitivas com GBTs [4], o desempenho das redes de features tabulares baseadas em DNNs pode variar drasticamente entre problemas. Por exemplo, um artigo de revisão [5] avaliou 19 modelos de features tabulares (NN + GBT) em 176 conjuntos de dados, e cada modelo teve o melhor desempenho em um conjunto de dados e o pior em outro, tornando desafiador adotar uma abordagem única para todos.
O primeiro passo em nossa abordagem foi alcançar paridade entre DNNs e modelos GBT apenas nas features tabulares. Selecionamos a arquitetura DCNv2 [6], pois mostrou sucesso em problemas relacionados em grande escala (por exemplo, utilizada pelo Google [6]). No entanto, os resultados iniciais mostraram um desempenho muito pior (-0,40%) para os modelos DCNv2 baseados em DNNs em comparação com os GBTs.
Em um artigo recente [7], os autores descobriram que incorporar atributos numéricos como embeddings atingiu ganhos significativos ao modelar features tabulares numéricas em DNNs. Esses embeddings numéricos são construídos usando ativações periódicas em diferentes frequências aprendidas. Combinamos isso com tabelas de embeddings treináveis para também facilitar embeddings de features categóricas. Incorporar essa estratégia de embedding no modelo DCNv2 nos permitiu alcançar paridade com os GBTs em muitos de nossos problemas internos.
Apesar de alcançar paridade apenas com features tabulares, o último desafio a superar foi incorporar embeddings de usuários baseados em transformer nesses modelos, mantendo ou superando o desempenho do modelo GBT com DNNs. Três fatores-chave foram críticos para alcançar isso. Primeiramente, usamos o DCNv2 para processar as features tabulares incorporadas e projetar o resultado em um embedding de baixa dimensão. Esse embedding de features é concatenado com o embedding baseado em transformer, e um perceptron de múltiplas camadas faz a predição final. Em segundo lugar, adicionar regularização na forma de decaimento de peso e/ou dropout nas camadas cruzadas do DCNv2 reduziu o overfitting. Finalmente, adicionar normalização aos embeddings baseados em transformer melhorou a consistência do DCNv2, permitindo que o modelo de DNN consistentemente e de maneira confiável superasse os GBTs. A figura abaixo mostra a melhoria relativa média em AUC para uma coleção de tarefas de benchmark em várias versões de nosso modelo DNN. Vemos que somente ao combinar o DCNv2 com os embeddings numéricos somos capazes de superar o baseline.
Apesar dos desafios em usar DNNs com dados tabulares, conseguimos desenvolver um modelo que funciona bem para nossas tarefas atuais de interesse, utilizando uma combinação do DCNv2 [6], embeddings numéricos, embeddings de features categóricas [7] e regularização. Usando esse modelo DCNv2 com as melhorias mencionadas, podemos treinar o modelo de fusão para combinar features e embeddings enquanto simultaneamente ajustamos o modelo transformer. A figura abaixo mostra a fusão de features tabulares como parte do processo de ajuste fino. A figura à direita abaixo mostra o pré-processamento e embedding de features tabulares em mais detalhes.
Na figura a seguir, visualizamos o ganho relativo em AUC ao usar fusão conjunta versus fusão tardia nas mesmas tarefas de benchmark mencionadas acima. Como anteriormente, o nosso baseline aqui é um modelo LightGBM treinado apenas com as features. Isso demonstra a vantagem de realizar o ajuste fino conjuntamente com features tabulares. Importante notar que, tanto no caso da fusão tardia quanto da fusão conjunta, a melhora não é obtida pela adição de novas fontes de informação. Em vez disso, a melhoria é alcançada aprendendo automaticamente features informativas para a tarefa em questão por meio do ajuste fino de nossos modelos fundacionais de transações.
Neste post, começamos motivando e introduzindo uma abordagem padrão de ajuste fino supervisionado para aprender embeddings adaptados a tarefas específicas. Em seguida, apresentamos a fusão conjunta, que nos permite combinar conjuntos de features tabulares existentes com nossos embeddings durante o ajuste fino. A fusão conjunta facilita a melhoria do desempenho a partir de nossos embeddings de usuários, ao mesmo tempo em que incorpora qualquer solução existente baseada em features tabulares. Por fim, demonstramos a melhoria gerada pela fusão conjunta em benchmarks internos.
Se você chegou até aqui, aproveite para acessar os demais posts da série e entender com mais profundidade o contexto e os detalhes técnicos dessa abordagem.
Resumo da série
Se você chegou até aqui, aproveite para acessar os demais posts da série e entender com mais profundidade o contexto e os detalhes técnicos dessa abordagem.
Conheça nossas oportunidades
References
[1] Borisov, V., Leemann, T., Seßler, K., Haug, J., Pawelczyk, M., & Kasneci, G. (2022). Deep neural networks and tabular data: A survey. IEEE transactions on neural networks and learning systems.
[2] Chen, T., & Guestrin, C. (2016, August). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining (pp. 785-794).
[3] Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., … & Liu, T. Y. (2017). Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems, 30.
[4] Zabërgja, G., Kadra, A., & Grabocka, J. (2024). Tabular Data: Is Attention All You Need?. arXiv preprint arXiv:2402.03970.
[5] McElfresh, D., Khandagale, S., Valverde, J., Prasad C, V., Ramakrishnan, G., Goldblum, M., & White, C. (2024). When do neural nets outperform boosted trees on tabular data?. Advances in Neural Information Processing Systems, 36.
[6] Wang, R., Shivanna, R., Cheng, D., Jain, S., Lin, D., Hong, L., & Chi, E. (2021, April). Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. In Proceedings of the web conference 2021 (pp. 1785-1797).
[7] Gorishniy, Y., Rubachev, I., & Babenko, A. (2022). On embeddings for numerical features in tabular deep learning. Advances in Neural Information Processing Systems, 35, 24991-25004.
[8] Imrie, F., Denner, S., Brunschwig, L. S., Maier-Hein, K., & Van Der Schaar, M. (2025). Automated ensemble multimodal machine learning for healthcare. IEEE Journal of Biomedical and Health Informatics.
Conheça nossas oportunidades