
most read
Software Engineering
Why We Killed Our End-to-End Test Suite Sep 24
Product
Product Managers: what they do and why we need them Feb 15
Software Engineering
The value of canonicity Oct 30
Careers
We bring together great minds from diverse backgrounds who enable discussion and debate and enhance problem-solving.
Learn more about our careers




Author: Denis Reis
How can you trust a model to support financial decisions if you can’t understand its decisions? For us, this wasn’t just an academic question. It was a core requirement for security, debugging, and responsible deployment. Here, at Nubank, we are leveraging the advent of transformer-based architectures, which have enabled the development of foundation models that automatically discover general features and learn representations directly from raw transaction data. By processing sequences of transactions (often by converting them into tokens like a natural language model would), these systems can efficiently summarize complex financial behavior.
In this post, we explore the explainability of such models, that is, the ability to examine how a single transaction, and its individual properties, influences the final prediction produced by a model. In this new scenario, where we have a transformer that processes a sequence of transactions, standard tools come with some limitations and requirements that make them difficult to maintain in a rapidly evolving environment like ours. However, we adopt a simpler approach, Leave One Transaction Out (LOTO), which can provide a good assessment of the impact of transactions (and their properties) on the final model prediction, while being easily compatible with virtually any model architecture.
Why Explainability is Crucial for Transaction Foundation Models
Understanding how the input influences the output of these models is paramount for responsible deployment, continuous improvement, and, critically, for monitoring and preventing exploitation.
How to Explain?
When addressing model explainability, a standard approach in both literature and industry is SHAP [1], a powerful framework for local explainability that has several beneficial properties for our use case.
For each data point, SHAP assigns a value, which we’ll henceforth refer to as importance, to each component of the input that represents how much that component is pushing the model’s prediction away from a baseline prediction (usually, the average prediction of a dataset that is provided as “background data”). For example, if the SHAP value of an attribute is large for a particular data point, that feature is pushing the model’s prediction of that data point upwards. We can move from these local explainability assessments to a global one by aggregating the SHAP values, such as the average absolute value, across several data points.
In our context, our input is a sequence of transactions, which for transformers are represented as a sequence of large embeddings. In this scenario, when assessing the relevance of transactions as a whole on the model’s prediction, SHAP values of the individual embedding dimensions aren’t relevant. Fortunately, in such cases, SHAP can group these smaller parts into transaction inputs and assign a single SHAP value to each transaction as a whole.
Another very positive aspect of SHAP is that it is model architecture-agnostic: we can compute SHAP values regardless of how the model operates internally. This property is especially relevant for us, since we are exploring several different architectures, including hybrid architectures that combine both neural networks and tree-based models.
Although SHAP satisfies our explainability requirements, unfortunately, it is computationally prohibitive for deep neural network use cases like ours. This has led to the exploration of more efficient, gradient-based approximations, such as Integrated Gradients [2] or Layer-Wise Relevance Propagation (LRP) [3]. However, while more efficient, we lose some of the properties of SHAP that are valuable to us, which makes adopting these other approaches challenging.
The first challenge is that, unlike SHAP, these methods cannot group components together to obtain a single importance for the entire transaction; we would need to aggregate these individual values in some way. We investigated different aggregation schemes for gradient-based attributions, and the ones we considered to be the best tended to use absolute values. The problem, in this case, is that they end up disregarding directionality (i.e., whether a transaction pushed the prediction up or down).
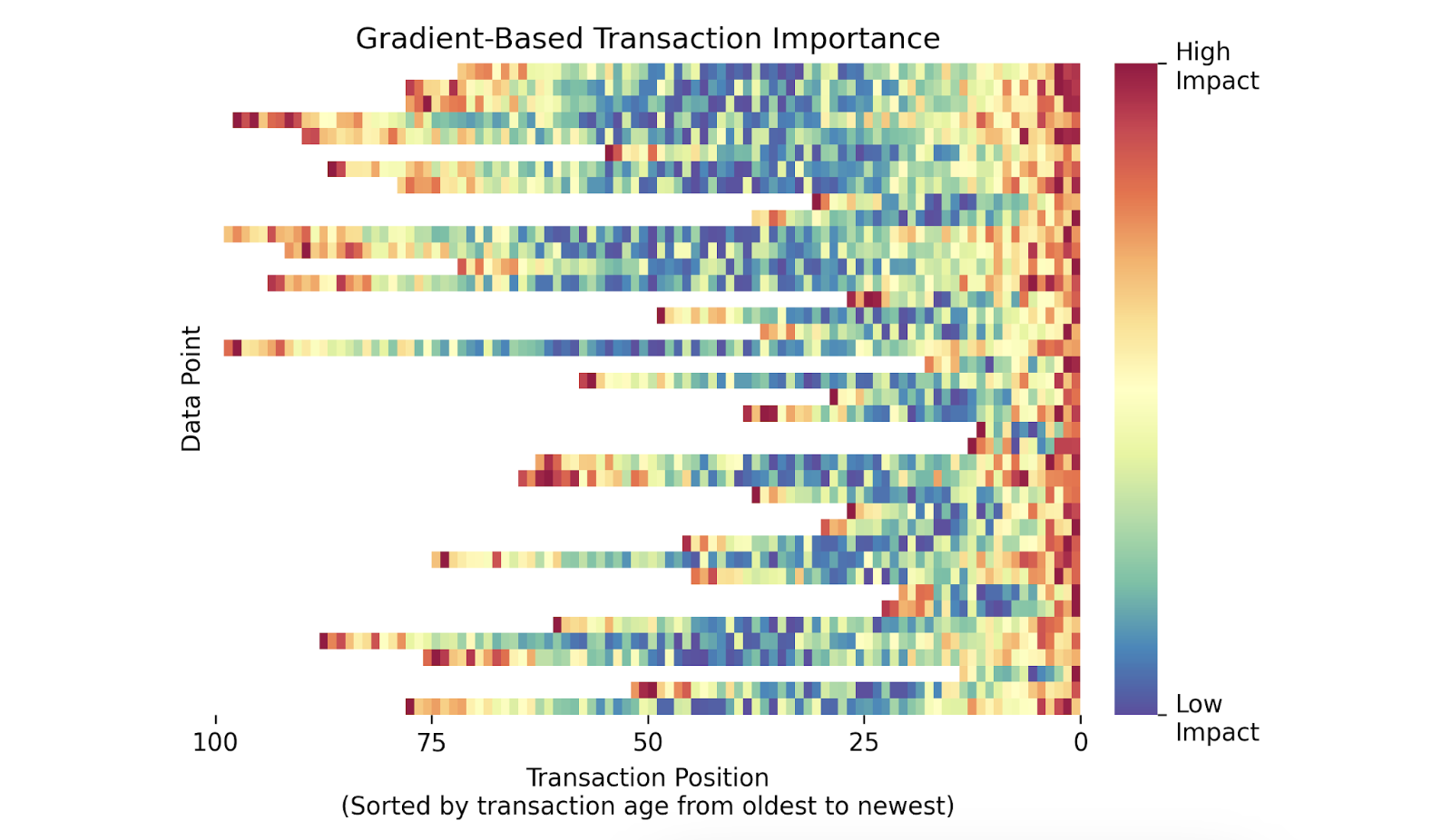
Moreover, in our particular case, we couldn’t easily separate the importance that a transaction has due to its attributes (value, weekday, etc) from its position in the sequence: the model seemed to assign high importance to the first and last transactions in a sequence, regardless of their other characteristics. We hypothesize this is likely due to how the model “understands” the sequence, that is, the structure of the input data. This bias is visualized in the figure below, where importance scores are heavily concentrated at both ends of the transaction sequence. Disclaimer: this figure, as well as the other figures displayed in this post, is based on synthesized data that illustrates the behavior observed on our real data.
A last challenge with these gradient-based methods is that they are not architecture-agnostic, imposing specific requirements for the types of models they can work with. First, the models need to be differentiable and provide access to their internal gradients, which was incompatible with some architectures we were examining. Second, some particular methods impose even more restrictive constraints regarding architectures or require intricate, domain-specific configurations. For instance, Layer-Wise Relevance Propagation (LRP) [5] demands specific propagation rules for each type of layer in the model. Even a more general method like Integrated Gradients (IG) introduces a critical implementation challenge: the non-trivial task of selecting a domain-specific baseline input vector that represents a “neutral” input. Keeping these restrictive, model-specific explainability tools in sync with our rapid pace of development was becoming too costly.
Lastly, another architecture-agnostic alternative we considered was LIME (Local Interpretable Model-agnostic Explanations) [4]. However, LIME introduces its own complexities: it requires generating a new dataset of perturbations and fitting a surrogate model for every individual explanation. This adds computational overhead, a layer of approximation, and requires defining a non-trivial perturbation strategy for our transactional data.These challenges led us to a simpler, more direct solution, Leave One Transaction Out (LOTO), that still fully satisfies our needs. It retains architecture-agnosticism, provides meaningful, directional values that associate the impact of transactions to predictions, and provides explainability at both local and global levels.
Leave One Transaction Out (LOTO)
A consistent characteristic across all the model architectures we examined is their ability to handle arbitrary sequences of transactions of varying length. This ability provides a very simple way to measure a transaction’s true contextual marginal impact: we just remove it and see what happens. Leave One Transaction Out (LOTO).
The method is straightforward: remove each transaction from a customer’s sequence one at a time and measure the difference between the new prediction and the original one. This directly reveals the impact of that specific transaction in that specific fixed context. It asks the simple question, “What was the direct contribution of this particular transaction’s presence to the prediction, considering the presence of all other transactions (the context)?” We can refer to this contribution as a LOTO value.
It’s important to clarify what “removing” means in this context. This is not like traditional feature ablation, which would be analogous to altering the feature space (e.g., modeling P(y | a=i, b=j) instead of the original P(y | a=i, b=j, c=k)).
Since our models are designed to process variable-length sets or sequences of transactions, “removing” one is simply a change in the input data for a single prediction, while the model’s architecture remains fixed. Conceptually, it’s like the difference between assessing P(y | … transaction_c=PRESENT) and P(y | … transaction_c=ABSENT). We are just feeding the model a sequence with one less element to see how its output changes.
The main drawback is that LOTO only tests transactions one by one. This means we miss out on interaction effects. For example, a payment to a utility company might be unimportant on its own, but when combined with a large, unexpected cash withdrawal, the two together might have a big impact. LOTO can’t capture this combined effect (what we call interaction effects). We accepted this trade-off for the vast gains in simplicity and computational efficiency, reserving more complex interaction analyses for future work.
We apply LOTO in two distinct modes: a global analysis to understand general trends by randomly choosing and removing one transaction from each customer in a large set, and a local analysis for deep dive debugging by removing every transaction, one at a time, from a single customer’s sequence. In either case, each removed transaction creates a new variant of the original input that the model must process. In the former case, since we remove only one transaction from each data point, the total number of variants is the same as the number of data points in the dataset. With hundreds of thousands to millions of these data points, we can build robust aggregations or even train simple meta-models (like a decision tree) on the LOTO results to automatically discover rules like, “Transactions of type X over amount Y consistently have a negative impact”.
For example, as illustrated in the figure below, we could identify that the type of transaction has a clear bias on the impact of a certain binary target. Once again, the figure is based on synthesized data for illustrative purposes.
For a deep, local analysis of a single customer, we remove each of their transactions one by one, generating hundreds of variants for each customer. This is substantially more computationally expensive than gradient-based techniques, which generally require running the model only once. For this reason, we reserve local analyses for specific deep dives. However, in this regard, LOTO provides a clearer picture of a transaction’s importance, free from the positional bias that can mislead gradient-based methods. By directly measuring the impact of removing a transaction, LOTO helps distinguish whether a transaction is important because of its content or simply because of its location in the sequence. As the figure below illustrates, LOTO reveals a much more even distribution of high-impact transactions, helping us accurately diagnose the model’s behavior.
Note that, in the figure above, it is still visible that more recent transactions are frequently more impactful. Another way of visualizing this in the global analysis is by simply checking the correlation between the age of a transaction and its impact on the prediction, as shown below.
Conclusion: Simplicity as a Feature
In our journey to build a reliable and interpretable financial AI system, we found that the simplest explainability method was also the most effective. By directly measuring the impact of removing each transaction, LOTO provides clear, actionable, and unbiased insights that are robust to our evolving model architecture.
References
[1] Lundberg, S. M., & Lee, S. I. (2017). A Unified Approach to Interpreting Model Predictions. Advances in Neural Information Processing Systems, 30. arXiv. https://arxiv.org/abs/1705.07874
[2] Sundararajan, M., Taly, A., & Yan, Q. (2017). Axiomatic Attribution for Deep Networks. Proceedings of the 34th International Conference on Machine Learning, 70, 3319-3328. arXiv. https://arxiv.org/abs/1703.01365
[3] Bach, S., Binder, A., Montavon, G., Klauschen, F., Müller, K. R., & Samek, W. (2015). On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE, 10(7), e0130140. https://doi.org/10.1371/journal.pone.0130140 [4] Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1135–1144. https://arxiv.org/abs/1602.04938
Check our job opportunities