
mais lidos
Life at Nu
Conheça a sede do Nubank em Pinheiros, São Paulo/Brasil jan 11
Design
A nova aparência do Nubank: conheça nossa nova logo maio 17
Culture & Values
Como os valores e a cultura da Nu moldam os produtos que criamos ago 7
Carreiras
Reunimos grandes mentes de diversas origens que permitem a discussão e o debate e melhoram a resolução de problemas.
Saiba mais sobre nossas carreiras




Author: Denis Reis
Como confiar em um modelo que apoia decisões financeiras se não conseguimos entender suas escolhas? Para nós, essa não era apenas uma questão teórica. Era um requisito central para segurança, depuração (debugging) e implementação responsável. Aqui no Nubank, estamos aproveitando o avanço das arquiteturas baseadas em transformer, que possibilitaram o desenvolvimento de modelos de base (foundation models) que automaticamente descobrem recursos gerais e aprendem representações diretamente dos dados brutos de transações. Ao processar sequências de transações (muitas vezes convertendo-as em “tokens”, como faria um modelo de linguagem natural), esses sistemas conseguem resumir eficientemente comportamentos financeiros complexos.
Neste post, vamos explorar a explicabilidade desses modelos, ou seja, a capacidade de examinar como uma única transação, e suas propriedades individuais, influencia a previsão final produzida pelo modelo. Neste novo cenário, onde um transformer processa uma sequência de transações, as ferramentas padrão apresentam limitações e exigências que tornam sua manutenção difícil em um ambiente de rápida evolução como o nosso. Por isso, adotamos uma abordagem mais simples: o Leave One Transaction Out (LOTO), ou “Remova Uma Transação”. Ele pode fornecer uma boa avaliação do impacto das transações (e suas propriedades) na previsão final, sendo facilmente compatível com praticamente qualquer arquitetura de modelo.
Por Que a Explicabilidade é Crucial para Modelos de Transação
Entender como o input (entrada) influencia o output (saída) desses modelos é essencial para a implementação responsável, melhoria contínua e, crucialmente, para o monitoramento e a prevenção de explorações maliciosas.
Como Explicar?
Ao abordar a explicabilidade de modelos, uma abordagem padrão na literatura e na indústria é o SHAP [1], uma poderosa estrutura para explicabilidade local que possui várias propriedades benéficas para o nosso caso de uso.
Para cada ponto de dado, o SHAP atribui um valor — que chamaremos de importância — a cada componente da entrada, representando o quanto esse componente está afastando a previsão do modelo de uma previsão de linha de base (geralmente, a previsão média de um conjunto de dados fornecido como “dados de fundo”). Por exemplo, se o valor SHAP de um atributo é grande para um ponto de dado específico, essa característica está empurrando a previsão do modelo daquele ponto para cima. Podemos passar dessas avaliações de explicabilidade local para uma global, agregando os valores SHAP, como o valor absoluto médio, em vários pontos de dados.
Em nosso contexto, nossa entrada é uma sequência de transações, que para transformers são representadas como uma sequência de grandes embeddings. Neste cenário, ao avaliar a relevância das transações como um todo na previsão do modelo, os valores SHAP das dimensões individuais do embedding não são relevantes. Felizmente, em tais casos, o SHAP pode agrupar essas partes menores em entradas de transação e atribuir um único valor SHAP a cada transação como um todo.
Outro aspecto muito positivo do SHAP é que ele é agnóstico à arquitetura do modelo: podemos calcular os valores SHAP independentemente de como o modelo opera internamente. Essa propriedade é especialmente relevante para nós, já que estamos explorando diversas arquiteturas diferentes, incluindo arquiteturas híbridas que combinam redes neurais e modelos baseados em árvores.
Embora o SHAP satisfaça nossos requisitos de explicabilidade, infelizmente, ele é computacionalmente proibitivo para casos de uso de deep neural networks como o nosso. Isso levou à exploração de aproximações mais eficientes e baseadas em gradiente, como o Integrated Gradients (IG) [2] ou o Layer-Wise Relevance Propagation (LRP) [3]. Contudo, embora mais eficientes, perdemos algumas das propriedades do SHAP que são valiosas para nós, o que torna a adoção dessas outras abordagens desafiadora.
O primeiro desafio é que, diferentemente do SHAP, esses métodos não conseguem agrupar componentes para obter uma única importância para a transação inteira; precisaríamos agregar esses valores individuais de alguma forma. Investigamos diferentes esquemas de agregação para atribuições baseadas em gradiente, e os que consideramos melhores tendiam a usar valores absolutos. O problema, neste caso, é que eles acabam desconsiderando a direcionalidade (ou seja, se uma transação empurrou a previsão para cima ou para baixo).
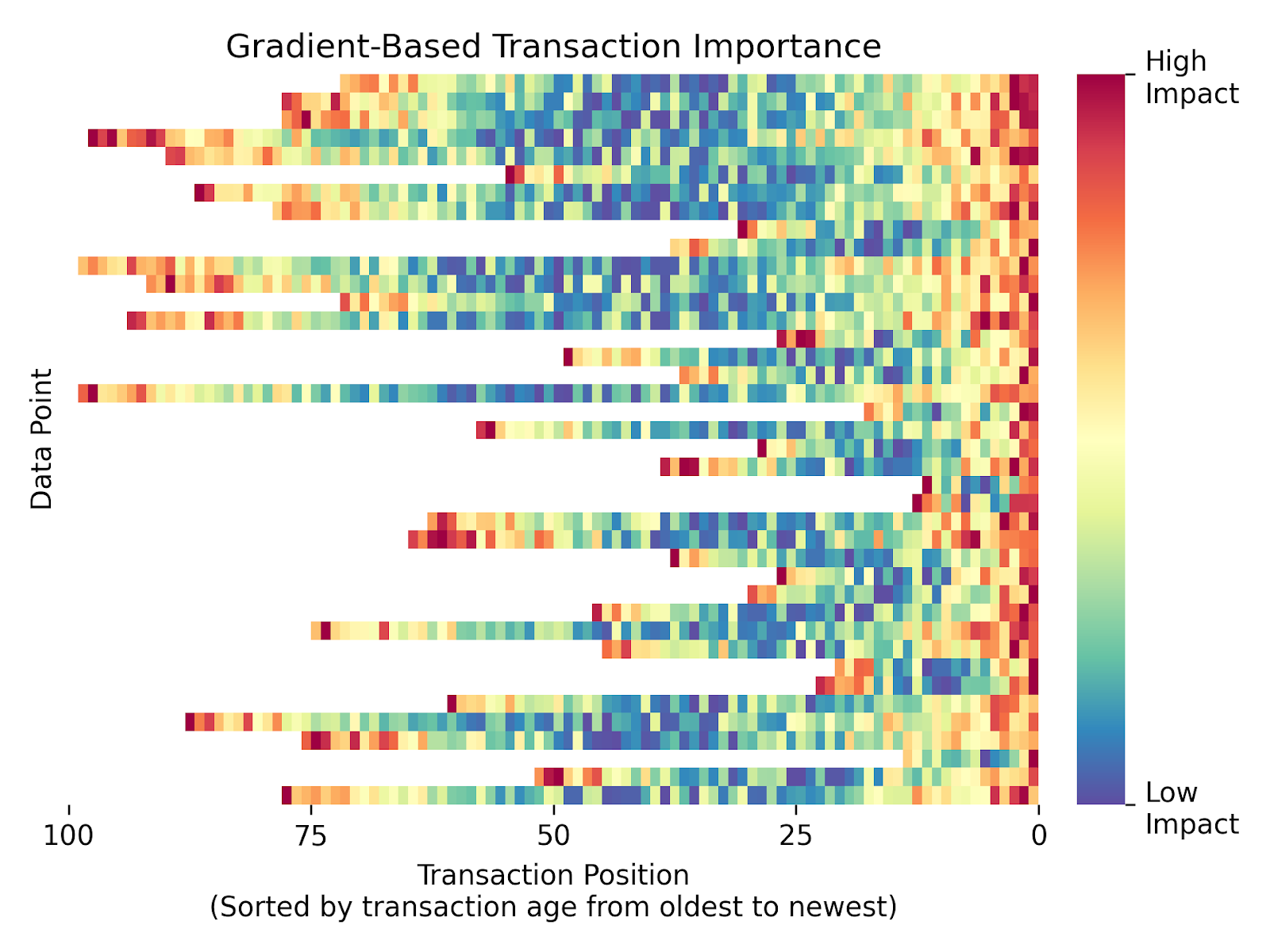
Além disso, em nosso caso particular, não conseguimos separar facilmente a importância que uma transação tem devido aos seus atributos (valor, dia da semana, etc.) da sua posição na sequência: o modelo parecia atribuir alta importância às primeiras e últimas transações em uma sequência, independentemente de suas outras características. Levantamos a hipótese de que isso se deve provavelmente à forma como o modelo “entende” a sequência, ou seja, a estrutura dos dados de entrada. Esse viés é visualizado na figura abaixo, onde os escores de importância estão fortemente concentrados em ambas as extremidades da sequência de transações. Aviso: esta figura, bem como as outras figuras exibidas neste post, é baseada em dados sintetizados que ilustram o comportamento observado em nossos dados reais.
Outro ponto é que métodos baseados em gradiente não são agnósticos à arquitetura: precisam de modelos diferenciáveis e acesso aos gradientes internos — o que é incompatível com algumas das arquiteturas que estudamos. Além disso, certos métodos impõem regras específicas por tipo de camada (como o LRP) ou exigem a definição de entradas “neutras” complexas (como o IG). Isso tornava a manutenção desses métodos muito custosa frente à nossa velocidade de desenvolvimento.
Por fim, também avaliamos o LIME (Local Interpretable Model-Agnostic Explanations) [4], outra alternativa agnóstica à arquitetura. Mas o LIME exige gerar novos conjuntos de dados com perturbações e treinar modelos substitutos para cada explicação — o que aumenta o custo computacional e introduz novas camadas de complexidade.
Esses desafios nos levaram a uma solução mais simples e direta — o LOTO (Leave One Transaction Out) — que continua atendendo às nossas necessidades, mantendo a compatibilidade com qualquer arquitetura, entregando valores direcionais e oferecendo explicabilidade local e global.
Leave One Transaction Out (LOTO)
Uma característica comum entre todas as arquiteturas que usamos é a capacidade de lidar com sequências variáveis de transações. Isso permite medir o impacto marginal real de uma transação de forma simples: basta removê-la e observar o que muda.
O método é direto: remova cada transação da sequência do cliente, uma de cada vez, e meça a diferença entre a nova previsão e a previsão original. Isso revela diretamente o impacto daquela transação específica naquele contexto fixo. Perguntamos: “Qual foi a contribuição direta da presença desta transação em particular para a previsão, considerando a presença de todas as outras (o contexto)?” Referimo-nos a essa contribuição como Valor LOTO.
É importante esclarecer o que significa “remover” neste contexto. Isso não é como a ablação tradicional de atributos, que seria análoga a alterar o espaço de atributos (por exemplo, modelar P(y | a=i, b=j) em vez do original P(y | a=i, b=j, c=k)).
Como nossos modelos são projetados para processar conjuntos ou sequências de transações de comprimento variável, “remover” uma é simplesmente uma mudança nos dados de entrada para uma única previsão, enquanto a arquitetura do modelo permanece fixa. Conceitualmente, é como a diferença entre avaliar P(y | … transaction_c=PRESENT) e P(y | … transaction_c=ABSENT). Estamos apenas alimentando o modelo com uma sequência com um elemento a menos para ver como sua saída muda.
O principal inconveniente é que o LOTO testa as transações apenas uma por uma. Isso significa que perdemos os efeitos de interação. Por exemplo, um pagamento a uma concessionária pode ser irrelevante por si só, mas quando combinado com um grande saque inesperado, os dois juntos podem ter um grande impacto. O LOTO não consegue capturar esse efeito combinado (o que chamamos de efeitos de interação). Aceitamos essa troca pelos vastos ganhos em simplicidade e eficiência computacional, reservando análises de interação mais complexas para trabalhos futuros.
Aplicamos o LOTO em dois modos distintos: uma análise global para entender tendências gerais, escolhendo e removendo aleatoriamente uma transação de cada cliente em um grande conjunto, e uma análise local para depuração profunda, removendo cada transação, uma de cada vez, da sequência de um único cliente.
Em ambos os casos, cada transação removida cria uma nova variante da entrada original que o modelo deve processar. No primeiro caso, como removemos apenas uma transação de cada ponto de dado, o número total de variantes é o mesmo que o número de pontos de dado no dataset. Com centenas de milhares a milhões desses pontos de dado, podemos construir agregações robustas ou até mesmo treinar meta-modelos simples (como uma árvore de decisão) nos resultados do LOTO para descobrir automaticamente regras como: “Transações do tipo X acima do valor Y consistentemente têm um impacto negativo”.
Por exemplo, como ilustrado na figura abaixo, pudemos identificar que o tipo de transação tem um viés claro no impacto sobre um certo alvo binário. Mais uma vez, a figura é baseada em dados sintetizados para fins ilustrativos.
Para uma análise local aprofundada de um único cliente, removemos cada uma de suas transações, uma por uma, gerando centenas de variantes para cada cliente. Isso é substancialmente mais custoso computacionalmente do que as técnicas baseadas em gradiente, que geralmente exigem executar o modelo apenas uma vez. Por esse motivo, reservamos as análises locais para deep dives específicos. No entanto, nesse aspecto, o LOTO fornece uma imagem mais clara da importância de uma transação, livre do viés posicional que pode enganar os métodos baseados em gradiente. Ao medir diretamente o impacto da remoção de uma transação, o LOTO ajuda a distinguir se uma transação é importante pelo seu conteúdo ou simplesmente por sua posição na sequência. Como a figura abaixo ilustra, o LOTO revela uma distribuição muito mais uniforme de transações de alto impacto, ajudando a diagnosticar com precisão o comportamento do modelo.
Note que, na figura acima, ainda é visível que transações mais recentes são frequentemente mais impactantes. Outra forma de visualizar isso na análise global é simplesmente verificando a correlação entre a idade de uma transação e seu impacto na previsão, como mostrado abaixo.
Conclusão: A Simplicidade como Atributo
Em nossa jornada para construir um sistema de IA financeira confiável e interpretável, descobrimos que o método de explicabilidade mais simples foi também o mais eficaz. Ao medir diretamente o impacto da remoção de cada transação, o LOTO fornece insights claros, acionáveis e imparciais que são robustos em relação à nossa arquitetura de modelo em constante evolução.
Referências
[1] Lundberg, S. M., & Lee, S. I. (2017). A Unified Approach to Interpreting Model Predictions. Advances in Neural Information Processing Systems, 30. arXiv. https://arxiv.org/abs/1705.07874
[2] Sundararajan, M., Taly, A., & Yan, Q. (2017). Axiomatic Attribution for Deep Networks. Proceedings of the 34th International Conference on Machine Learning, 70, 3319-3328. arXiv. https://arxiv.org/abs/1703.01365
[3] Bach, S., Binder, A., Montavon, G., Klauschen, F., Müller, K. R., & Samek, W. (2015). On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE, 10(7), e0130140. https://doi.org/10.1371/journal.pone.0130140 [4] Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1135–1144. https://arxiv.org/abs/1602.04938
Conheça nossas oportunidades