
mais lidos
Life at Nu
Conheça a sede do Nubank em Pinheiros, São Paulo/Brasil jan 11
Design
A nova aparência do Nubank: conheça nossa nova logo maio 17
Culture & Values
Como os valores e a cultura da Nu moldam os produtos que criamos ago 7
Carreiras
Reunimos grandes mentes de diversas origens que permitem a discussão e o debate e melhoram a resolução de problemas.
Saiba mais sobre nossas carreiras




Autor: Fabio Souza
No Nubank, estamos constantemente ampliando os limites de como a Inteligência Artificial pode nos ajudar a compreender melhor as jornadas financeiras de nossos clientes. Nossos posts anteriores detalharam como utilizamos modelos de base baseados em transformadores para converter sequências de dados de transação em embeddings poderosos, permitindo-nos atender melhor às necessidades financeiras de nossos clientes no momento certo [1, 4]. Exploramos a interface que traduz dados brutos de transações em embeddings que nossos modelos podem entender [2], discutimos as nuances de ajustar esses modelos para tarefas específicas [3], e demonstramos como otimizamos narrativas de usuários selecionando e representando cuidadosamente características e fontes de transação [5].
No entanto, a jornada mencionada de otimizar narrativas de usuários é contínua. Como destacamos em nossos posts anteriores, a escolha de qual informação de uma transação incluir e como representá-la é importante, especialmente dado o contexto limitado das nossas arquiteturas de transformadores. Hoje, nos aprofundamos em um aspecto crucial dos dados de transação: o timestamp de quando a transação ocorreu. A forma como codificamos o “quando” de uma transação pode impactar significativamente a capacidade de um modelo de base em entender o estado financeiro de um cliente e prever comportamentos futuros.
No restante deste post do blog, primeiro discutimos os desafios de usar timestamps absolutos. Em seguida, propomos uma abordagem diferente que utiliza deltas de tempo para representar a informação temporal, detalhando o processo de design e decisões-chave. Por fim, apresentamos o desenho experimental e os resultados que validam essa nova abordagem em um problema real de negócios.
O Desafio com Carimbos de Data/Hora Absolutos
Inicialmente, para representar transações, nossos modelos de nível de token usavam carimbos de data/hora absolutos, codificados por tokens especiais como <MÊS>, <DIA> e <DIA DA SEMANA> para cada operação. Apesar de ser um método simples, essa abordagem criava vários desafios para um modelo fundacional, que é feito para criar representações de usuários ao longo de períodos extensos. A figura a seguir mostra o procedimento de tokenização de transações que nossos modelos [2,4] já usavam.
Imagine que um cliente fica inativo por um longo período, como um ano, e depois volta a fazer transações. Se o modelo depender apenas de carimbos de data/hora absolutos, as representações (embeddings) geradas durante o período de inatividade seriam sempre as mesmas. Ou seja, o modelo não tem uma “noção do agora”. Essa falta de sensibilidade aos períodos de inatividade faz com que as representações possam não refletir com precisão o comportamento atual do cliente. Essa capacidade é, na verdade, algo inerente a recursos de aprendizado de máquina tradicionais, que são calculados ao longo do tempo em relação a uma “data de pontuação” (por exemplo, 1 mês, 3 meses, 6 meses).
Além disso, a codificação com carimbos de data/hora absolutos pode fazer com que os modelos se ajustem excessivamente a períodos de datas específicas ou a combinações de <MÊS><DIA><DIA DA SEMANA> e outros atributos de transação. Isso acontece principalmente se os dados de treinamento cobrirem menos de um ano inteiro ou se o objetivo tiver uma forte sazonalidade. Isso limita a capacidade do modelo de generalizar de forma eficaz durante a inferência, especialmente para dados que estão fora do período de treinamento (out-of-time – OOT).
Conheça nossas oportunidades
Introdução às Diferenças de Tempo: Uma Abordagem Relativa
Para solucionar as limitações das codificações de tempo absoluto, levantamos a hipótese de que seria mais eficaz representar a informação de tempo como um “delta de tempo”, ou a “idade” da transação em relação à data de pontuação (o “agora”). Essa abordagem permite que as representações (embeddings) reflitam os períodos de inatividade e captem melhor a relevância e a recência de transações passadas.
Assim como fizemos com outros atributos de transação, implementamos essa abordagem ao criar um token especial. Mais especificamente, quantizamos os deltas de tempo em “baldes” distintos, de forma semelhante a como lidamos com os valores das transações. Esses baldes são então representados por seus próprios tokens especiais, como:
É importante notar que há dois hiperparâmetros que precisamos escolher. Primeiro, a granularidade/escala dos deltas de tempo deve ser selecionada. Em segundo lugar, precisamos definir um limite a partir do qual os deltas de tempo são truncados. No exemplo acima, o limite de truncamento do delta de tempo foi definido como dois anos. Assim, nesse caso, qualquer transação que esteja a mais de dois anos da data de pontuação é truncada para o token: <DELTA DE TEMPO: ACIMA-DE-2-ANOS>. Na seção a seguir, exploramos a definição desses parâmetros ao analisar a distribuição dos deltas de tempo em nossos dados.
Definindo o Horizonte e a Granularidade do Delta de Tempo
Como mencionado, uma etapa importante para usar de forma eficaz os tokens especiais de delta de tempo é definir de forma sensata o limite máximo de truncamento do delta de tempo. Por exemplo, escolher um limite muito pequeno pode levar à perda de informações valiosas. Por outro lado, um limite excessivamente grande pode introduzir um número exagerado de tokens especiais, que podem ser mal treinados se a ocorrência deles for rara durante a fase de treinamento.
Ao traçar a distribuição cumulativa dos tamanhos das janelas temporais de transação (o tempo entre a transação mais antiga e a mais recente em uma sequência) para nosso conjunto de dados de treinamento, observamos que quase 97% das sequências continham transações de até dois anos atrás. Com base nisso, decidimos começar a usar dois anos como limite para a nossa codificação de delta de tempo. Em seguida, precisamos escolher uma granularidade para os “baldes” de delta de tempo. Experimentamos duas estratégias de baldes diferentes:
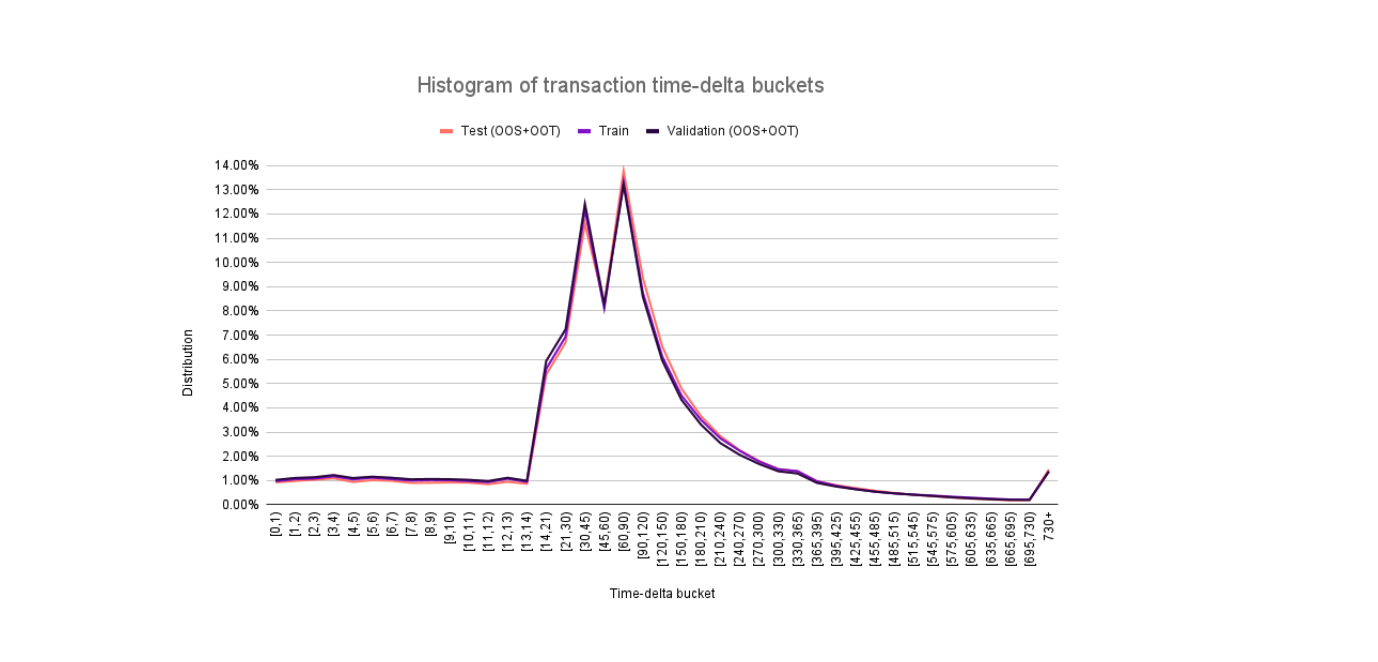
Usando a estratégia padrão, plotamos o histograma dos baldes de delta de tempo, comparando as distribuições nos conjuntos de dados de treino, validação e teste. Podemos ver que as distribuições são consistentes nas três divisões do conjunto de dados, o que é um sinal positivo para a generalização no período fora do tempo (out-of-time). A estratégia menos granular tem uma distribuição semelhante.
Desenho Experimental e Resultados
Para testar de forma rigorosa nossa hipótese de que uma representação de tempo relativa é melhor que uma absoluta, pré-treinamos quatro variantes de modelos fundacionais no mesmo conjunto de dados, usando a tarefa de previsão do próximo token. Em seguida, ajustamos cada variante do modelo para uma tarefa específica, utilizando um conjunto de dados rotulados para um problema de negócios. As variantes foram:
Para deixar clara a distinção entre essas variantes, vamos analisar um exemplo de como cada uma codifica um conjunto de transações. Vamos considerar um usuário que tem as seguintes 4 transações (com data, descrição e valor):
Então, usando a data de pontuação de 31/08/2025, 00:00:00 AM, obteríamos os seguintes tokens para as representações de tempo:
Após pré-treinar e ajustar cada uma das variantes, avaliamos os quatro modelos em um conjunto de dados de teste que continha informações de um período posterior, o que reflete de forma mais precisa o desempenho em um ambiente de produção real. A principal métrica de avaliação foi a AUC. A figura abaixo mostra o delta da AUC em comparação com a variante de linha de base.
Principais Conclusões:
Neste trabalho, descobrimos que a forma como representamos a informação temporal pode impactar significativamente a capacidade do modelo de base em entender o comportamento financeiro do cliente. Codificar o tempo como deltas de tempo em vez de datas absolutas aumentou o ROC-AUC em 0,2 pontos percentuais (pp), ao mesmo tempo que reduziu o número de tokens por transação em cerca de 15%, permitindo histórias de transação mais longas dentro do mesmo orçamento de tokens. Esses achados ressaltam um princípio fundamental: a forma como projetamos nossa representação de dados pode ter um impacto substancial no desempenho do modelo. Os resultados mais fracos do ajuste de delta de tempo menos granular destacam ainda mais a importância da experimentação e avaliação sistemáticas para alcançar resultados ótimos.
Referências
[1] Braithwaite, D., & Udagawa, H. (2025, 24 de Março). Entendendo as finanças dos nossos clientes por meio de modelos fundacionais. Building Nubank. https://building.nubank.com/pt-br/entendendo-as-financas-dos-nossos-clientes-por-meio-de-modelos-fundacionais/
[2] Braithwaite, D., & Udagawa, H. (2025, 22 de Abril). Definindo uma interface entre dados de transações e modelos fundacionais. Building Nubank. https://building.nubank.com/pt-br/definindo-uma-interface-entre-dados-de-transacoes-e-modelos-fundacionais/
[3] Braithwaite, D., Cavalcanti, M., & Udagawa, H. (2025, 14 de Maio). Ajuste Fino de Modelos de Usuários de Transações. Building Nubank. https://building.nubank.com/pt-br/ajuste-fino-de-modelos-de-usuarios-de-transacoes/
[4] Braithwaite, D. T., Cavalcanti, M., McEver, R. A., et al (2025). Your Spending Needs Attention: Modeling Financial Habits with Transformers. arXiv preprint arXiv:2507.23267.
[5] Foust, T. (2025, 29 de julho). Otimização de Narrativas de Usuários para Modelos Fundacionais. Building Nubank.https://building.nubank.com/pt-br/otimizacao-narrativas-usuarios-modelos-fundacionais/
Conheça nossas oportunidades