
mais lidos
Life at Nu
Conheça a sede do Nubank em Pinheiros, São Paulo/Brasil jan 11
Design
A nova aparência do Nubank: conheça nossa nova logo maio 17
Culture & Values
Como os valores e a cultura da Nu moldam os produtos que criamos ago 7
Carreiras
Reunimos grandes mentes de diversas origens que permitem a discussão e o debate e melhoram a resolução de problemas.
Saiba mais sobre nossas carreiras




Autores: Daniel Braithwaite, Arissa Yoshida, Rafael Celente e Aman Gupta
Em posts anteriores [1,2,3], apresentamos a abordagem do Nubank para usar modelos fundacionais baseados em dados de transações para resolver problemas preditivos [4]. Esses textos descreveram como estruturamos nossos dados de transações para modelos fundacionais [2], como pré-treinamos esses modelos e, finalmente, como os refinamos (via joint fusion) para tarefas específicas [3]. É importante destacar que observamos grandes avanços em tarefas críticas para o Nubank. O resultado mais significativo foi que essas melhorias não vieram do uso de fontes adicionais de dados, mas sim do aprendizado de representações ótimas de transações, em vez de usar features construídas manualmente.
Apesar de poderosos, esses modelos fundacionais são custosos de treinar do ponto de vista computacional. No Nubank, buscamos constantemente maneiras de melhorar a eficiência de dados, tanto para reduzir custos quanto para construir modelos com desempenho superior. Neste post, exploramos como um novo otimizador, o Muon [5], está nos ajudando a alcançar esses objetivos. O Muon tem recebido grande atenção da comunidade de pesquisa em LLMs, especialmente por ser mais eficiente no uso de amostras para atingir um nível de qualidade fixo no pré-treinamento, quando comparado ao AdamW (que, até então, é a escolha padrão na maioria dos treinamentos de grande escala).
A qualidade de nossos modelos fundacionais aumenta em função da quantidade de dados usados, chegando a mais de 203 milhões de linhas. Por exemplo, na Figura 1, demonstramos como o AUC do conjunto de teste para um de nossos modelos menores (24 milhões de parâmetros) escala em função do número de pontos de dados utilizados em joint fusion. Mesmo melhorias pequenas, como um aumento de 0,05% no AUC, são altamente valiosas, pois podem significar economias de milhões de dólares para o Nubank. No entanto, à medida que o AUC melhora, o custo de treinamento também cresce. O joint fusion [3] com 5 milhões de linhas leva cerca de 12 horas em 8 GPUs NVIDIA A100, enquanto com 40 milhões de linhas o tempo chega a aproximadamente 95 horas, usando as mesmas 8 A100s.
Esse custo computacional de treinar modelos mostra a importância de métodos que aumentem a eficiência de dados. Por outro lado, também significa que podemos alcançar melhor desempenho com o mesmo número de passos de treinamento. Existem diversos métodos possíveis para aumentar a eficiência de dados, mas neste post exploramos o uso do otimizador Muon [5] para tornar o pré-treinamento de nossos modelos fundacionais mais eficiente. Como consequência, esses modelos aprimorados geram economia de custos e melhor desempenho de produto para os clientes do Nubank.
O otimizador Muon [5] representa uma mudança significativa em relação às abordagens heurísticas dominantes, como o AdamW, ao introduzir um método de otimização de segunda ordem simples e derivado de princípios fundamentais. Projetado especificamente para camadas lineares densas de redes neurais, o mecanismo central do Muon pode ser descrito como um gradiente de descida íngreme estruturado em matrizes, com regularização por norma espectral. Sua operação fundamental envolve “ortogonalizar” a matriz de gradiente de cada camada de pesos, forçando os valores singulares a ficarem próximos de 1. Esse processo preserva a informação direcional do gradiente enquanto normaliza sua magnitude em todas as direções, evitando que a otimização seja dominada por poucos componentes ruidosos ou pouco úteis. Esse conceito, embora elegante do ponto de vista teórico, torna-se viável na prática pelo uso da iteração eficiente de Newton-Schulz [6], que aproxima a ortogonalização sem o custo computacional proibitivo de uma decomposição SVD completa.
Esse design baseado em princípios se traduz diretamente em ganhos substanciais de eficiência, tanto em dados quanto em computação. As atualizações de momento ortogonalizado do Muon permitem passos mais estáveis e diretos em direção ao mínimo da função de perda, além de possibilitar que o modelo aprenda mais com cada token processado. Os ganhos são significativos também do ponto de vista computacional: experimentos de scaling law mostram consistentemente que o Muon pode alcançar qualidade de modelo comparável à de modelos treinados com AdamW consumindo apenas cerca de metade (~52%) dos FLOPs de treinamento, o que equivale a uma melhoria de aproximadamente 2x em eficiência computacional [7,8].
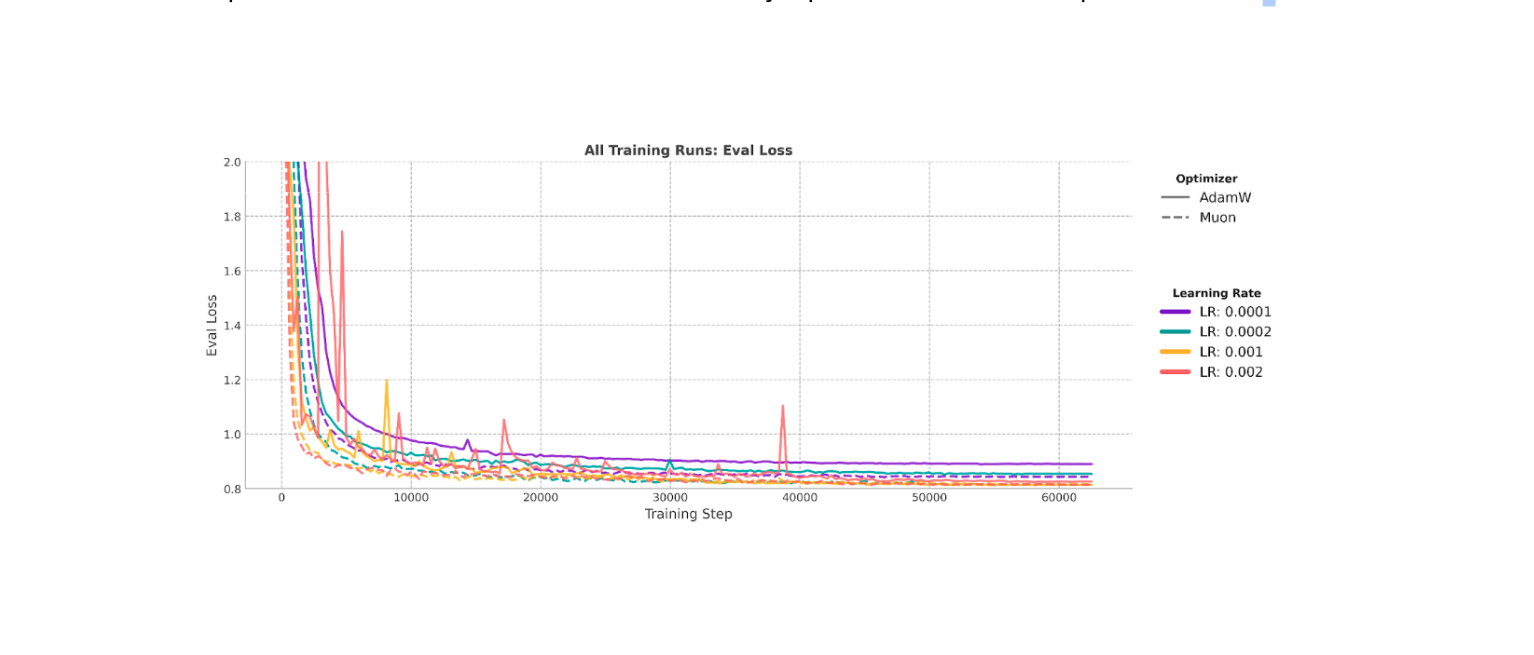
Para testar nossa hipótese de que o Muon pode levar a melhores modelos fundacionais para o Nubank, pré-treinamos vários modelos com 330 milhões de parâmetros em um dataset de 20 milhões de amostras. Comparamos o desempenho do Muon contra o amplamente utilizado AdamW em quatro taxas de aprendizado diferentes: 1e-4, 2e-4, 1e-3 e 2e-3. A figura abaixo mostra esses resultados. É importante notar que o Muon converge significativamente mais rápido que o AdamW e atinge soluções com perdas de validação menores em todas as taxas de aprendizado testadas.
Ao consolidarmos todos os experimentos em uma única comparação, observamos que os três melhores modelos foram: Muon 1e-3, Muon 2e-3 e AdamW 1e-3. Vale reforçar que os treinos com Muon convergiram mais rápido do que o melhor resultado obtido com AdamW. Esses achados confirmam nossa hipótese de que o uso do Muon pode treinar modelos fundacionais. Um ponto adicional: as perdas de previsão de próximo token são incomumente baixas para language modeling, pois os tokens especializados usados em nossos modelos de fundação possuem um vocabulário potencial restrito.
Neste post, demonstramos as vantagens de integrar o otimizador Muon ao pipeline de pré-treinamento dos modelos fundacionais do Nubank. Ao adotar o Muon, alcançamos convergência mais rápida e qualidade superior de modelos em comparação ao AdamW, destravando ganhos de eficiência de dados e computação. Esses avanços se traduzem diretamente em benefícios tangíveis para o Nubank: custos de treinamento reduzidos e desempenho aprimorado de produtos, o que, em última análise, proporciona uma experiência melhor para nossos clientes. Nossos resultados confirmam que técnicas de otimização sofisticadas, como o Muon, são cruciais para expandir os limites do que é possível com modelos fundacionais em larga escala, garantindo que continuemos inovando de forma eficiente e eficaz.
Referências
[1] Braithwaite, D., & Udagawa, H. (2025, March 24). Understanding our customers’ finances through foundation models. Building Nubank. https://building.nubank.com/understanding-our-customers-finances-through-foundation-models/
[2] Braithwaite, D., & Udagawa, H. (2025, April 22). Defining an interface between transaction data and foundation models. Building Nubank. https://building.nubank.com/defining-an-interface-between-transaction-data-and-foundation-models/
[3] Braithwaite, D., Cavalcanti, M., & Udagawa, H. (2025, May 14). Fine-tuning transaction user models. Building Nubank. https://building.nubank.com/fine-tuning-transaction-user-models/
[4] Braithwaite, D. T., Cavalcanti, M., McEver, R. A., et al (2025). Your Spending Needs Attention: Modeling Financial Habits with Transformers. arXiv preprint arXiv:2507.23267.
[5] Jordan, K., Jin, Y., Boza, V., You, J., Cesista, F., Newhouse, L., & Bernstein, J. (2024). Muon: An optimizer for hidden layers in neural networks. https://kellerjordan.github.io/posts/muon/
[6] Bernstein, J., & Newhouse, L. (2024). Old optimizer, new norm: An anthology. arXiv preprint arXiv:2409.20325.
[7] Shah, I., Polloreno, A. M., Stratos, K., Monk, P., Chaluvaraju, A., Hojel, A., … & Vaswani, A. (2025). Practical efficiency of muon for pretraining. arXiv preprint arXiv:2505.02222.
[8] Liu, J., Su, J., Yao, X., Jiang, Z., Lai, G., Du, Y., … & Yang, Z. (2025). Muon is scalable for LLM training. arXiv preprint arXiv:2502.16982.
Conheça nossas oportunidades